How one default parameter almost killed our servers
A short story about serious server issue caused by super minor thing.
Published: May 2, 2021 SponsoredDiscover new games to play, organize your library, read reviews and more.
This is a story about an issue we had to fix in one of the projects I am involved with. I basically woke up to Slack messages from my colleague who discovered that a couple of servers were basically out of RAM and somehow still worked thanks to swap.
I have to admit I am quite embarrassed by this mistake, but on the other hand web stuff is not my core competency (😃) and I want to share this as a cautionary tale.
When investigating the issue, we quite quickly found that there were lot's of scripts launched by cron running simultaneously. In normal circumstances, this particular script would finish long before it would be launched again by cron.
So something was keeping the scripts basically "stuck". And this was basically the reason why servers ran out of memory.
Below is chart showing number of processes which does a great job of illustrating the issue we had:
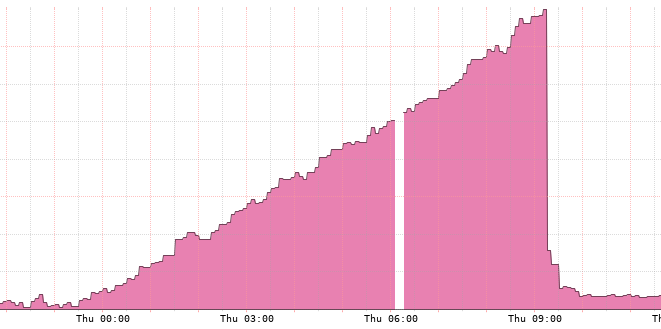
The drop is server restart and then hotfix patch.
While the script is fairly involved, in a nutshell it does a few requests to external service and processes the result. It is written in Python (because the project is itself a Django site) and uses the very popular requests library for making network calls.
Requests is one of the most downloaded Python package today, pulling in around 14M downloads / week— according to GitHub, Requests is currently depended upon by 500,000+ repositories. You may certainly put your trust in this code.
It is super easy to work with, in most basic usage you can just do something like:
response = requests.get(url)
And done. Works brilliantly.
Except there is a (in my mind) strange default regarding timeout. Because the default timeout is basically infinity. It will wait for connection until the end of time. And here it is. The explanation for why we had so many stuck scripts. And since each script needs the Python runtime with virtual environment, it quickly consumed the available RAM.
I have to admin when writing this script and the associated Python code, it did not even occur to me to consider timeouts. I am of course familiar with the concept but I just thought that there is some sensible default.
This is indeed the case in the Python and Django ecosystem which is great, but in this particular instance it wasn't. I am sure there probably were valid reasons to not timeout ever, but I would never have guessed it.
The issue is now fixed. I added timeouts to all the requests calls and we modified the script so there is no possibility that it can run more than once at any given time.
I think one of good takeaways is to execute scripts in a way that does not even allow multiple instances of the same script to run. And to pay more attention to your networking code.
Follow on Bluesky to not miss new posts

iOS blogger and developer with interest in Python/Django.